
在 Ubuntu 上安装大数据环境(Spark、Hadoop、HBase、Flume、Kafka、Zookeeper、MongoDB)
会有点子复杂,慢慢来。
注意:
请根据你所使用的 shell 确定你用户配置文件的名称,常用 shell 与其配置文件的对应关系为:
bash:~/.bashrc
zsh:~/.zshrc
可通过
echo $SHELL命令确定你当前系统所使用的 shell 类型我使用的是 zsh ,故后续写入环境变量操作部分是写入到
~/.zshrc中。

手动安装
一、apt / yum 换源
二、Java 8(JDK)
安装
Hadoop、Spark、HBase 等组件通常依赖 JDK 8,先完成 Java 的安装。
# 安装
sudo apt install openjdk-8-jdk -y # debian系
sudo yum install -y java-1.8.0-openjdk-devel # Red Hat系完成后使用
java -version命令验证安装
配置环境变量
使用
readlink -f $(which java)命令确认 Java 安装位置

使用以下命令将环境变量写入配置文件中,注意将命令中的路径替换为你实际的 Java 安装位置。
JAVA_HOME 变量应该指向 JDK 的根目录,而不是 bin/java 文件。通常,JAVA_HOME 应该是 jre/bin/java 目录的 上级目录,即:/usr/lib/jvm/java-8-openjdk-amd64
echo "export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64" >> ~/.zshrc
echo "export PATH=\$PATH:\$JAVA_HOME/bin" >> ~/.zshrc三、安装 Zookeeper
安装
下载 Zookeeper
wget https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz解压到 /usr/local/
# 解压到 /usr/local/ 并重命名
sudo tar -zxvf zookeeper-3.4.14.tar.gz -C /usr/local/
sudo mv /usr/local/zookeeper-3.4.14 /usr/local/zookeeper创建 zoo.cfg 配置文件
sudo cp /usr/local/zookeeper/conf/zoo_sample.cfg /usr/local/zookeeper/conf/zoo.cfg启动 Zookeeper
/usr/local/zookeeper/bin/zkServer.sh start配置
使用以下命令编辑 Zookeeper 的配置文件。
nano /usr/local/zookeeper/conf/zoo.cfg确保以下内容对应:
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/zookeeper/data
clientPort=2181创建数据目录并启动 Zookeeper
mkdir -p /usr/local/zookeeper/data
/usr/local/zookeeper/bin/zkServer.sh start执行
jps命令,查看结果
看到 QuorumPeerMain 进程,说明 Zookeeper 已经成功运行

四、Hadoop
安装
下载 Hadoop
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz解压到 /usr/local/ 并设置环境变量
# 解压到 /usr/local/ 并重命名
sudo tar -zxvf hadoop-2.7.7.tar.gz -C /usr/local/
sudo mv /usr/local/hadoop-2.7.7 /usr/local/hadoop
# 设置环境变量
echo "export HADOOP_HOME=/usr/local/hadoop" >> ~/.zshrc
echo "export PATH=\$PATH:\$HADOOP_HOME/bin:\$HADOOP_HOME/sbin" >> ~/.zshrc完成后使用命令
hadoop version验证 Hadoop 的安装
配置
使用命令
echo $JAVA_HOME查看 Java 的安装目录并记录

这里需要记录的结果是
/usr/lib/jvm/java-8-openjdk-amd64
修改 hadoop-env.sh
使用命令
sudo nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh修改 hadoop 的环境配置文件。按照如下说明修改。
# 在文件中找到export JAVA_HOME=...和export HADOOP_CONF_DIR=...两项
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 # 前面输出的 JAVA_HOME 路径
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop # 你的 HADOOP_HOME 值/etc/hadoop
# 注释掉以下内容
for f in $HADOOP_HOME/contrib/capacity-scheduler/*.jar; do
if [ "$HADOOP_CLASSPATH" ]; then
export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$f
else
export HADOOP_CLASSPATH=$f
fi
done修改完成后使用命令
source $HADOOP_HOME/etc/hadoop/hadoop-env.sh应用修改。如果忘记应用修改,会导致后面修改 hdfs-site.xml 时报错:

修改 core-site.xml
使用命令
nano $HADOOP_HOME/etc/hadoop/core-site.xml修改 hadoop 的核心配置文件确保文件中有以下配置
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>修改 hdfs-site.xml
使用命令
nano $HADOOP_HOME/etc/hadoop/修改 hdfs 的配置文件检查文件的以下配置
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>localhost:50090</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value> <!-- 单机测试可设为 1,生产环境建议 3 -->
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///usr/local/hadoop/tmp/dfs/data</value> <!-- 指定 DataNode 存储路径 -->
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>localhost:50070</value> <!-- NameNode Web 界面地址 -->
</property>
<property>
<name>dfs.permissions</name>
<value>false</value> <!-- 开发环境可禁用权限检查 -->
</property>
</configuration>配置本机 ssh 免密登录
Hadoop 采用 SSH 远程管理节点(即使是单机模式)
在默认环境下,哪怕是自连的 SSH 连接(
ssh user@localhost)也会被要求手动输入密码。
虽然 Namenode、Datanode 和 Secondary Namenode 都在 localhost 运行,但 start-dfs.sh 仍然尝试以 SSH 连接它们。
使用以下命令完成 ssh 免密登录的配置
ssh-keygen -t ed25519 -C "" # 输入这条命令后一直回车即可, -C 后的双引号可以填上自己的邮箱方便将生成的密钥对作他用
cat ~/.ssh/id_ed25519.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys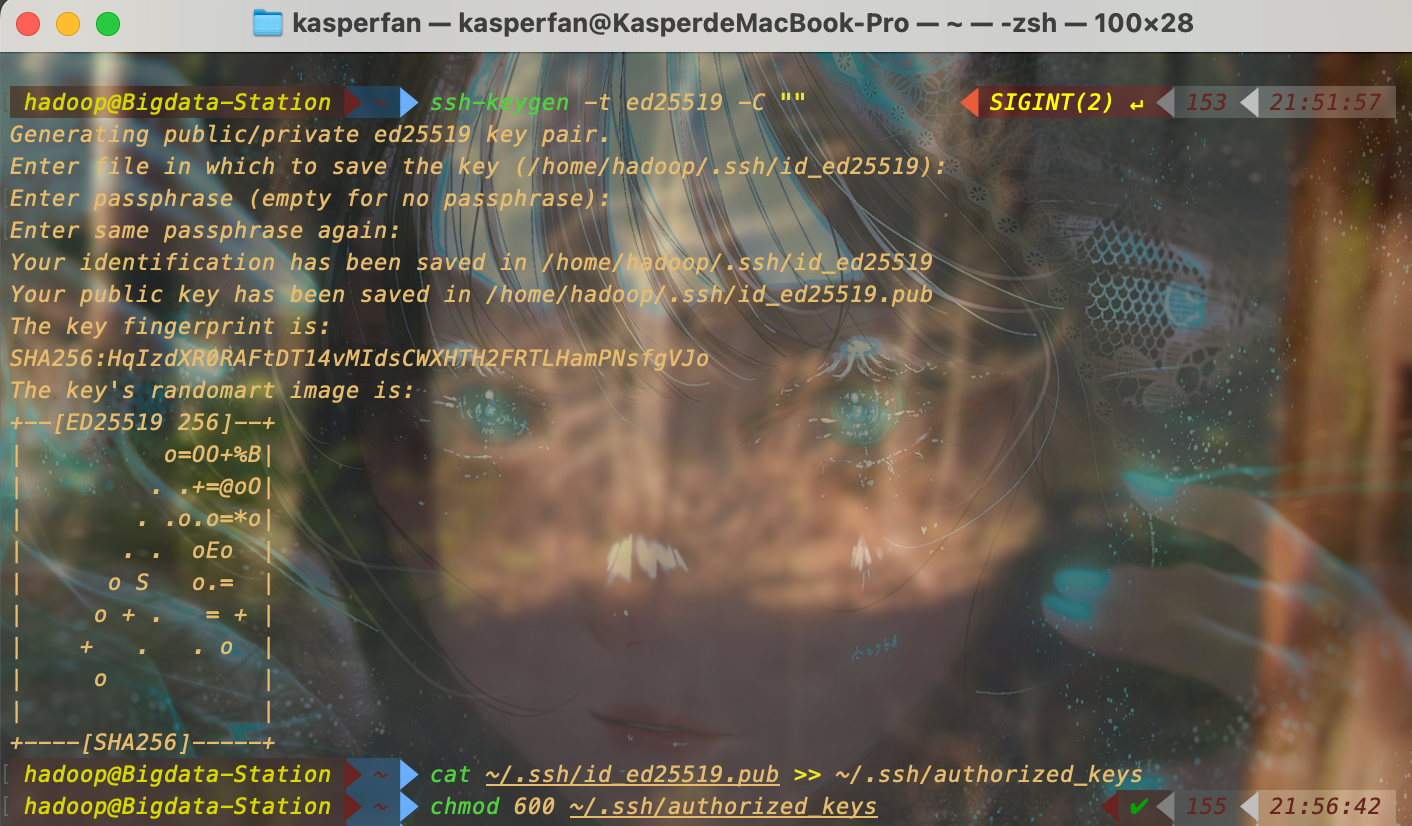
格式化 NameNode
如果之前的配置文件修改有误或者没有启动 NameNode ,在运行 hdfs 命令时会出现以下报错,需要在启动 NameNode 后格式化 NameNode 。

执行以下命令即可
hdfs namenode -format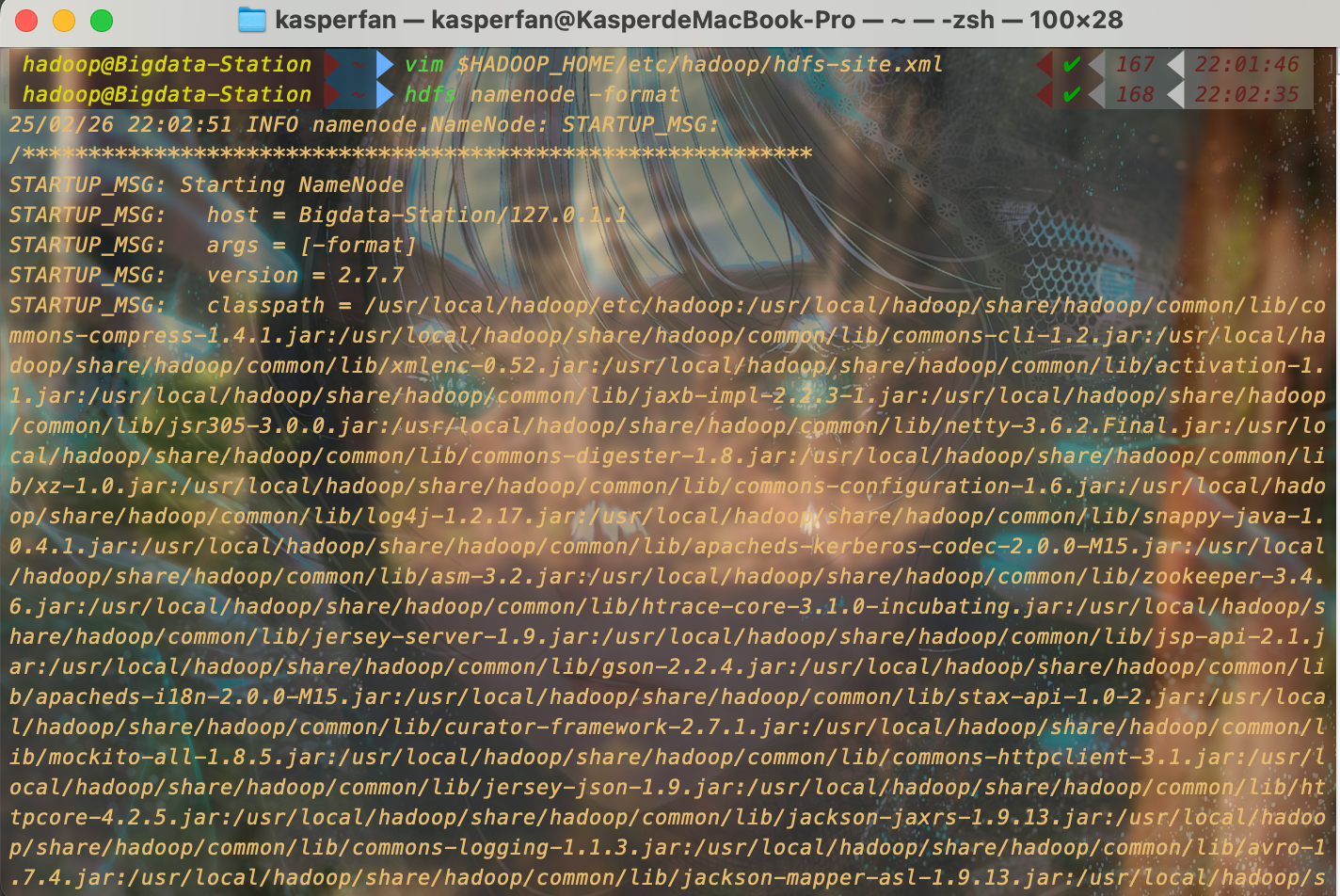
完成后依次执行以下命令:
start-dfs.shjps
如下图,有 NameNode 就完成了
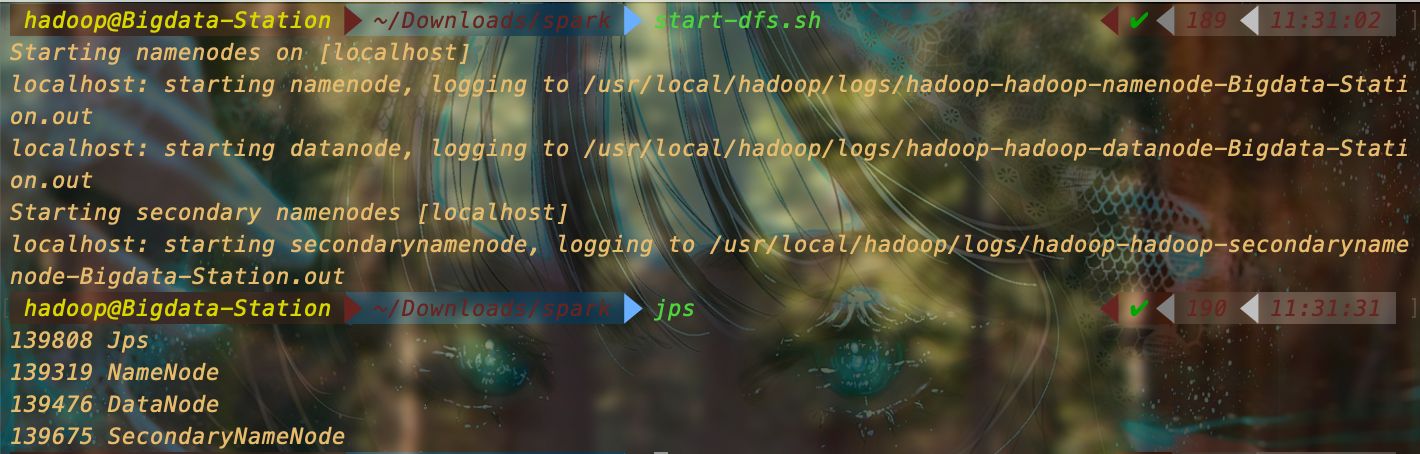
之后再执行 hdfs 命令就可以正常操作了

五、安装 HBase
安装
下载 HBase
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hbase/1.4.13/hbase-1.4.13-bin.tar.gz解压到 /usr/local/ 并设置环境变量
# 解压到 /usr/local/ 并重命名
sudo tar -zxvf hbase-1.4.13-bin.tar.gz -C /usr/local/
sudo mv /usr/local/hbase-1.4.13 /usr/local/hbase
# 设置环境变量
echo "export HBASE_HOME=/usr/local/hbase" >> ~/.zshrc
echo "export PATH=\$PATH:\$HBASE_HOME/bin" >> ~/.zshrc完成后使用命令
hbase version验证 Spark 的安装
配置
修改 HBase 配置文件 hbase-site.xml 。
命令:
vim $HBASE_HOME/conf/hbase-site.xml检查文件中是否有以下内容,若没有手动添加。
配置的意义为:
启动 HBase Web UI 在 16010 端口。
让 HBase 使用外部运行在 2181 端口的 Zookeeper 。
让 HBase 不启动自己内置的 Zookeeper 。
<configuration>
<property>
<name>hbase.master.info.port</name>
<value>16010</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>localhost</value> <!-- 指向你的 ZooKeeper 地址 -->
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value> <!-- 使用外部 ZooKeeper 的端口 -->
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>HBASE_MANAGES_ZK</name>
<value>false</value> <!-- 关闭内置 ZooKeeper -->
</property>
</configuration>修改HBase环境文件hbase-env.sh。
命令:
vim $HBASE_HOME/conf/hbase-env.sh作以下修改:
# 先弄清楚你自己的JAVA_HOME,然后设置好文件中的JAVA_HOME
export JAVA_HOME=#这里写上你之前装好Java之后设置的JAVA_HOME
# 如果你使用的是Java 8或以上的版本,需要注释掉原来的HBASE_MASTER_OPTS和HBASE_RESIONSERVER_OPTS,然后重新写
# 这样做的原因是Java 8已经弃用了被注释掉的内存管理方式
#export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m -XX:ReservedCodeCacheSize=256m"
#export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m -XX:ReservedCodeCacheSize=256m"
export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=256m -XX:ReservedCodeCacheSize=256m"
export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:MetaspaceSize=128m -XX:MaxMetaspaceSize=256m -XX:ReservedCodeCacheSize=256m"
# 如果你的HBase使用外部ZooKeeper,需要另添一行
export HBASE_MANAGES_ZK=false在HDFS中初始化Hbase的目录并赋权
hdfs dfs -mkdir -p /hbase
hdfs dfs -chown -R hbase:hbase /hbase
hdfs dfs -chmod -R 755 /hbase
hdfs dfs -setrep -w 1 /hbase/hbase.version启动 HBase 。
命令:
start-hbase.sh成功运行后使用浏览器访问
localhost:16010,出现以下界面说明 HBase Web UI 已经成功运行。
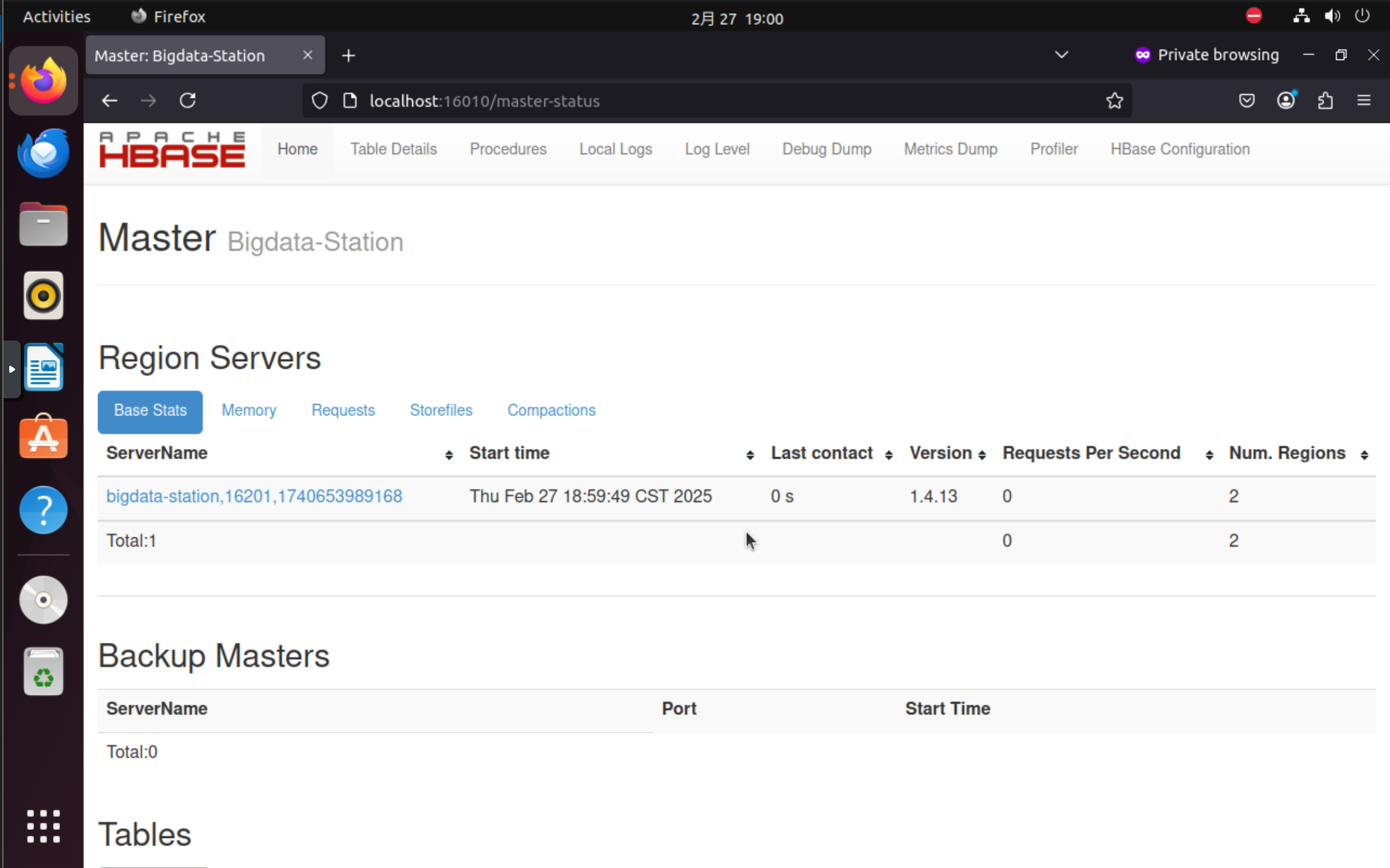
六、安装 Kafka
下载 Kafka
wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/0.10.2.2/kafka_2.11-0.10.2.2.tgz解压到 /usr/local/
# 解压到 /usr/local/ 并重命名
sudo tar -zxvf kafka_2.11-0.10.2.2.tgz -C /usr/local/
sudo mv /usr/local/kafka_2.11-0.10.2.2 /usr/local/kafka启动 Kafka
停止 Kafka 脚本(如有需要):
/usr/local/kafka/bin/kafka-server-stop.sh
sudo /usr/local/kafka/bin/zookeeper-server-start.sh -daemon /usr/local/kafka/config/zookeeper.properties
sudo /usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties检查 Kafka 启动状态
命令:
jps

NameNode/DataNode/SecondaryNameNode:Hadoop
HMaster/HRegionServer:HBase
QuorumPeerMain:Zookeeper
Kafka:Kafka
七、安装 Flume
Flume 用于将数据从外部系统(如文件、日志等)收集到 Kafka 或 HBase。
安装
下载 HBase
wget https://mirrors.tuna.tsinghua.edu.cn/apache/flume/1.9.0/apache-flume-1.9.0-bin.tar.gz解压到 /usr/local/ 并设置环境变量
# 解压到 /usr/local/ 并重命名
sudo tar -zxvf apache-flume-1.9.0-bin.tar.gz -C /usr/local/
sudo mv /usr/local/apache-flume-1.9.0-bin /usr/local/flume
# 设置环境变量
echo "export FLUME_HOME=/usr/local/flume" >> ~/.zshrc
echo "export PATH=\$PATH:\$FLUME_HOME/bin" >> ~/.zshrc配置
首先配置 Flume 的 agent 来将数据发送到 Kafka 。编辑Flume配置文件
nano /usr/local/flume/conf/flume.conf配置以下内容:
agent.sources = src
agent.channels = ch
agent.sinks = sink
agent.sources.src.type = exec
agent.sources.src.command = tail -f /var/log/syslog
agent.channels.ch.type = memory
agent.channels.ch.capacity = 1000
agent.channels.ch.transactionCapacity = 100
agent.sinks.sink.type = org.apache.flume.sink.kafka.KafkaSink
agent.sinks.sink.topic = test-topic
agent.sinks.sink.brokerList = localhost:9092
agent.sinks.sink.channel = ch启动 Flume
启动 Flume agent,命令如下:
sudo /usr/local/flume/bin/flume-ng agent --conf /usr/local/flume/conf --conf-file /usr/local/flume/conf/flume.conf --name agent验证 Flume 数据流向 Kafka
可以用 Kafka 的消费者命令验证 Flume 是否把数据成功写入 Kafka:
/usr/local/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test-topic --from-beginning八、安装 Spark
安装
下载 Spark
wget https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.4.0/spark-2.4.0-bin-hadoop2.7.tgz解压到 /usr/local/ 并设置环境变量
# 解压到 /usr/local/ 并重命名
sudo tar -zxvf spark-2.4.0-bin-hadoop2.7.tgz -C /usr/local/
sudo mv /usr/local/spark-2.4.0-bin-hadoop2.7 /usr/local/spark
# 设置环境变量
echo "export SPARK_HOME=/usr/local/spark" >> ~/.zshrc
echo "export SPARK_CONF_DIR=$SPARK_HOME/conf" >> ~/.zshrc
echo "export PATH=\$PATH:\$SPARK_HOME/bin:\$SPARK_HOME/sbin" >> ~/.zshrc完成后使用命令
spark-shell验证 Spark 的安装
配置
配置 spark-defaults.conf
$SPARK_HOME/conf 目录中包含 spark-defaults.conf.template 文件,需要复制它并进行修改:
cd $SPARK_HOME/conf
cp spark-defaults.conf.template spark-defaults.conf在 spark-defaults.conf 中添加以下配置来与 Kafka 和 Hadoop 集成:
配置 Spark 与 Hadoop 集成
# Hadoop 配置
spark.hadoop.fs.defaultFS=hdfs://namenode_host:8020
spark.hadoop.yarn.resourcemanager.address=resourcemanager_host:8032
spark.hadoop.yarn.application.classpath=/usr/local/hadoop/etc/hadoop/*:/usr/local/hadoop/share/hadoop/*:/usr/local/hadoop/share/hadoop/common/lib/*:/usr/local/hadoop/share/hadoop/common/*:/usr/local/hadoop/share/hadoop/mapreduce/lib/*:/usr/local/hadoop/share/hadoop/mapreduce/*:/usr/local/hadoop/share/hadoop/yarn/lib/*:/usr/local/hadoop/share/hadoop/yarn/*配置 Spark 与 Kafka 集成
# Kafka 配置
spark.kafka.bootstrap.servers=localhost:9092
spark.kafka.consumer.group.id=spark-consumer1. 配置 log4j.properties(可选)
为了更好的日志记录,你可以在 $SPARK_HOME/conf 中配置 log4j.properties,复制模板文件:
cp log4j.properties.template log4j.properties然后,你可以调整日志级别,例如:
log4j.rootCategory=INFO, console2. 配置 Spark 与 Zookeeper 集成(如果需要)
如果你想要使用 Spark Streaming 并与 Kafka 集成,你还需要确保 Spark 能连接到 Zookeeper。一般情况下,Kafka 使用 Zookeeper 来协调和管理消息队列的状态。你可以在 spark-defaults.conf 中添加以下配置:
# 配置 Kafka 使用的 Zookeeper
spark.streaming.kafka.maxRatePerPartition=1000
spark.streaming.kafka.consumer.cache.size=100启动 Spark 服务
完成配置后,你可以启动 Spark:
启动 Spark Master:
$SPARK_HOME/sbin/start-master.sh启动 Spark Worker:
$SPARK_HOME/sbin/start-worker.sh spark://<master-ip>:7077提交 Spark 应用程序
配置完成后,你可以提交 Spark 应用程序来测试集成。例如,提交一个与 Kafka 集成的 Spark Streaming 应用:
$SPARK_HOME/bin/spark-submit \
--class com.example.KafkaSparkStreaming \
--master spark://<master-ip>:7077 \
--conf spark.kafka.bootstrap.servers=localhost:9092 \
--conf spark.kafka.consumer.group.id=spark-consumer \
/path/to/your/spark-kafka-streaming-app.jar检查 Spark 任务
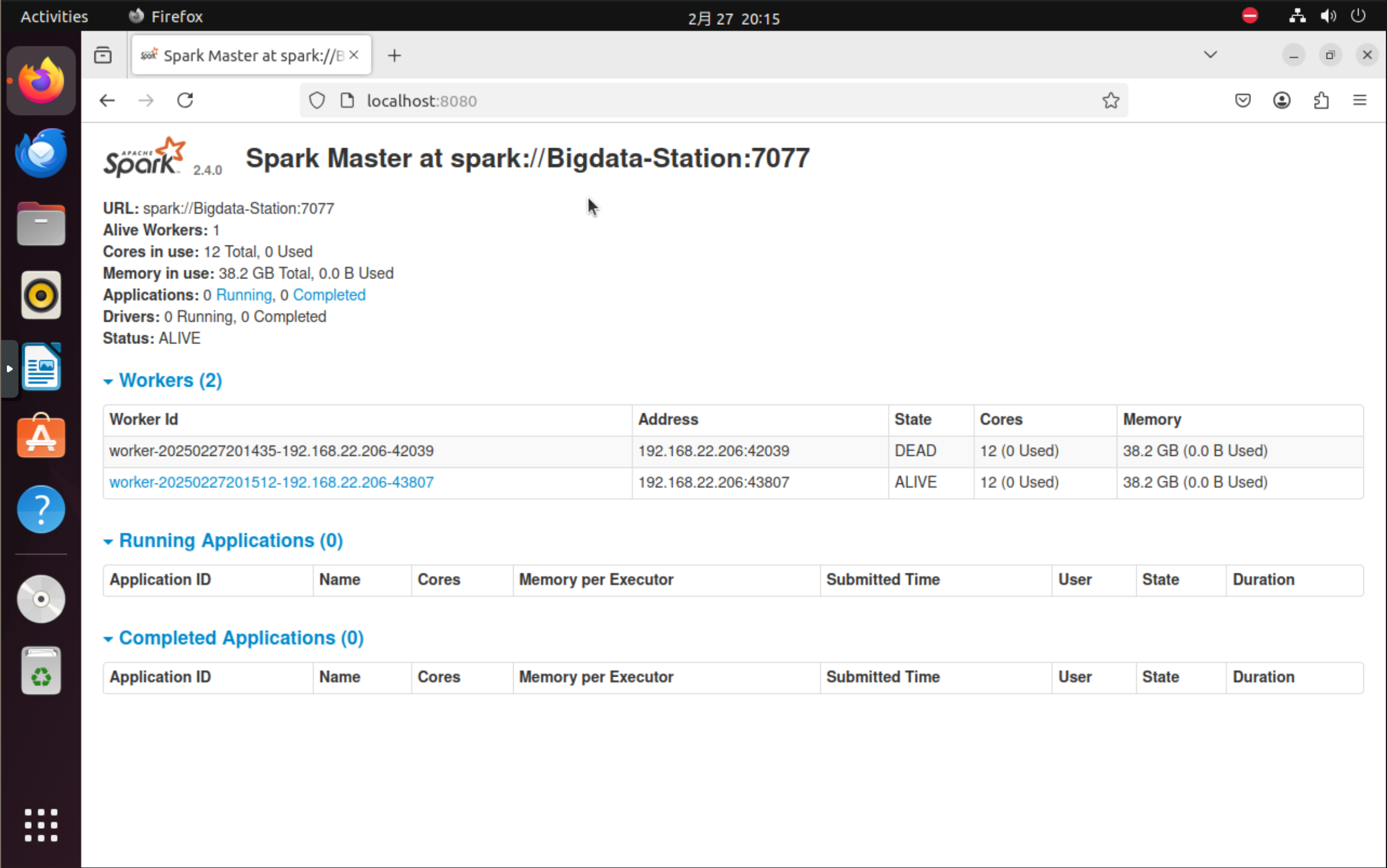
你可以通过 Spark Web UI 来检查任务的状态,通常可以通过浏览器访问 http://<master-ip>:8080。
脚本一键安装
不包含自动配置,后续添加
sudo apt install openjdk-8-jdk -y
echo "export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64" >> ~/.zshrc
echo "export PATH=\$PATH:\$JAVA_HOME/bin" >> ~/.zshrc
# hadoop
sudo tar -zxvf hadoop-2.7.7.tar.gz -C /usr/local/
sudo mv /usr/local/hadoop-2.7.7 /usr/local/hadoop
echo "export HADOOP_HOME=/usr/local/hadoop" >> ~/.zshrc
echo "export PATH=\$PATH:\$HADOOP_HOME/bin:\$HADOOP_HOME/sbin" >> ~/.zshrc
# spark
sudo tar -zxvf spark-2.4.0-bin-hadoop2.7.tgz -C /usr/local/
sudo mv /usr/local/spark-2.4.0-bin-hadoop2.7 /usr/local/spark
echo "export SPARK_HOME=/usr/local/spark" >> ~/.zshrc
echo "export PATH=\$PATH:\$SPARK_HOME/bin:\$SPARK_HOME/sbin" >> ~/.zshrc
# hbase
sudo tar -zxvf hbase-1.4.13-bin.tar.gz -C /usr/local/
sudo mv /usr/local/hbase-1.4.13 /usr/local/hbase
echo "export HBASE_HOME=/usr/local/hbase" >> ~/.zshrc
echo "export PATH=\$PATH:\$HBASE_HOME/bin" >> ~/.zshrc
# zookeeper
sudo tar -zxvf zookeeper-3.4.14.tar.gz -C /usr/local/
sudo mv /usr/local/zookeeper-3.4.14 /usr/local/zookeeper
sudo cp /usr/local/zookeeper/conf/zoo_sample.cfg /usr/local/zookeeper/conf/zoo.cfg
sudo /usr/local/zookeeper/bin/zkServer.sh start
# kafka
sudo tar -zxvf kafka_2.11-0.10.2.2.tgz -C /usr/local/
sudo mv /usr/local/kafka_2.11-0.10.2.2 /usr/local/kafka
sudo /usr/local/kafka/bin/zookeeper-server-start.sh -daemon /usr/local/kafka/config/zookeeper.properties
sudo /usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
# flume
sudo tar -zxvf apache-flume-1.9.0-bin.tar.gz -C /usr/local/
sudo mv /usr/local/apache-flume-1.9.0-bin /usr/local/flume
echo "export FLUME_HOME=/usr/local/flume" >> ~/.zshrc
echo "export PATH=\$PATH:\$FLUME_HOME/bin" >> ~/.zshrc大数据组件启动顺序
